Este artigo explica como podemos usar o recurso de extração personalizado do Screaming Frog SEO para extrair informações de um site. O recurso de extração personalizado permite que você extraia praticamente qualquer conteúdo do código fonte HTML.
Como exemplo apresento diversas extração personalizadas. Você pode copiar os exemplos e modificar as expressões para se adaptarem ao seu cenário.
Por que usar a extração personalizada? Screaming Frog, por padrão, coleta muitas informações relevantes que auxilia a análise de SEO, como: títulos de página, elementos H1 e h2, tags canônicas etc. Mas e se você quiser extrair algumas informações como H3 e H4, ou contar o número de ocorrência de um determinado elemento. Isso pode se necessário para lhe ajudar na reestruturação da arquitetura da informações do site, por exemplo.
O que é o XPath?
Linguagem de consulta utilizada para localizar e processar itens em documentos XML. As expressões XPath podem ser usadas em HTML também, já que possui uma estrutura hierárquica semelhante ao XML. É uma ferramenta versátil para navegar pelos elementos e atributos de um documento HTML e extrair seu conteúdo.
Além do XPath temos no Screaming Frog as opções de CSSPath e Regex. Eu particularmente tenho preferência em usar o XPath e uso com mais frequência que os outros métodos de extração.
Como usar a extração personalizada do Screaming Frog
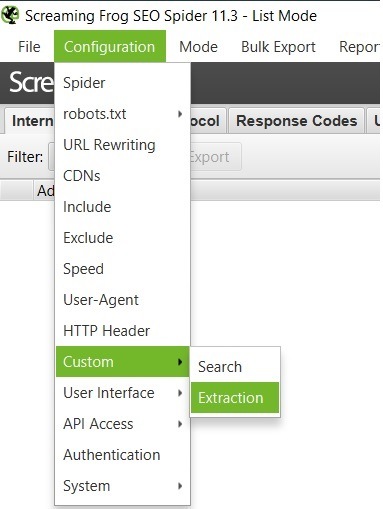
Para acessar o recurso Extração personalizada Clique em Configuration > Custom > Extraction.
Temos 10 campos que podem ser personalizados para extrair informações de páginas HTML. Abaixo apresento parte dessa janela onde configuramos as regras de extração:
A janela abaixo pode variar de acordo com a versão do seu programa
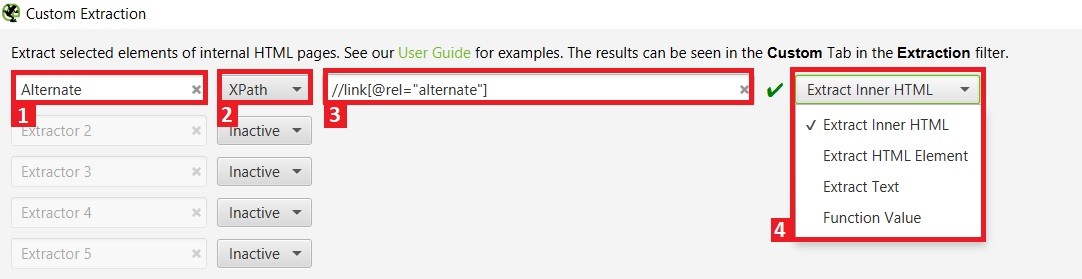
- Nome da extração: Você pode digitar um nome para a pesquisa. Nome que aparecerá nas extrações personalizadas e no arquivo de exportação do Excel;
- Método de extração: Escolha a opção XPath;
- Regra: Inserir a sintaxe XPath. Screaming Frog incluir um indicador de validação de sintaxe. Um X vermelho indica que a sintaxe é inválida, Já um V verde significa que está correto;
- Tipo de extração: Escolha Extract Inner HTML (Extrair HTML interno), Extract HTML Element (Extrair elemento do HTML), Extract Text (Extrair texto) ou Function Value (valor da função).
Tipos de extração
- Extract Inner HTML: o conteúdo HTML interno do elemento selecionado. Caso o elemento selecionado tenha outros elementos HTML, eles serão incluídos na extração;
- Extract HTML Element: o elemento selecionado e seu conteúdo HTML interno são extraídos;
- Extract Text: o conteúdo do elemento alvo na regra XPath e o texto de qualquer elemento interno;
- Function Value: utilizado para uma escrever uma função de extração.
Exemplos extração
| XPath | Resultado | Extração |
|---|---|---|
| Opções de extração Screaming Frog | ||
| /descendant::h1[1] | KADUNEW | Extract Text |
| /descendant::h1[1] | <h1><a href=”https://www.kadunew.com/blog/” title=”KADUNEW”>KADUNEW</a></h1> | Extract HTML Element |
| /descendant::h1[1] | <a href=”https://www.kadunew.com/blog/” title=”KADUNEW”>KADUNEW</a> | Extract Inner HTML |
Sintaxe Básica de Extração
| Exemplo | Descrição |
|---|---|
| Extrações básicas para XPath screaming frog | |
| // | Pesquise em qualquer lugar do documento |
| / | Pesquisar na raiz |
| @ | Selecione um atributo específico de um elemento |
| * | Curinga, usado para selecionar qualquer elemento |
| [ ] | Encontre um elemento específico |
| . | Especifica o elemento atual |
| .. | Especifica o elemento pai |
Exemplo de extração personalizada
Nas tabelas abaixo, você pode copiar a sintaxe na coluna exemplo e colá-la no Screaming Frog para executar a extração descrita na coluna descrição. Atente-se para ajustar a sintaxe como desejar, personalizando a extração de acordo com suas necessidades.
Extração de Elementos HTML
| Exemplo | Descrição |
|---|---|
| Extração de elementos HTML Screaming Frog | |
| //h1 | Extrair todas tags H1 |
| //h2[1] | Extrair a primeira tag H2 |
| //h3[2] | Extrair a segunda tag H3 |
| //div/p | Extrair qualquer <p> que seja filho de <div> |
| //div[@class=”author”] | Extrair qualquer <div> com class “author” |
| //p[@class=”bio”] | Extrair qualquer <p> com class “bio” |
| //*[@class=”bio”] | Extrair qualquer elemento HTML com class “bio” |
| //ul/li[last()] | Extrair o último <li> de um <ul> |
| //ol[@class=”cat”]/li[1] | Extrair o primeiro <li> de um <ol> com a class “cat” |
| count(//h2) | Conta o número de H2’s (definir filtro Extrairion para “Function Value”) |
| //a[contains(.,”SEO”)]/@href | Extrair todos links com o texto texto âncora “SEO” |
| //a[contains(translate(., ‘ABCDEFGHIJKLMNOPQRSTUVWXYZ’, ‘abcdefghijklmnopqrstuvwxyz’),’seo spider’)]/@href | Extrair todos links com o texto texto âncora “SEO”. Por ser Case-sensitive a regra converte tudo para minúsculo |
| //a[starts-with(@title,”Written by”)] | Extrair qualquer link com atributo title iniciando com “Written by” |
| //p[contains(text() ,”your search query here”)] | Extrair um texto específico dentro de um parágrafo |
| /descendant::h3[1] | Extrai o conteúdo do primeiro H3 rastreado |
| /descendant::h3[position() >= 0 and position() <= 10] | Extrai os 10 primeiros H3s rastreados |
| //h3[contains(text(), “exemplo”)] | Extrai conteúdo “exemplo” de qualquer H3 |
Extração de Atributos HTML
| Exemplo | Descrição |
|---|---|
| Extraindo conteúdo de atributo HTML Screaming Frog | |
| //@href | Extrair todos links |
| //a[starts-with(@href,”mailto”)]/@href | Extrair link que iniciam “mailto” (endereço de e-mail) |
| //img/@src | Extrair URLs de todas imagens |
| //img[contains(@class,”aligncenter”)]/@src | Extrair URLs das imagens contendo a classe de nome “aligncenter” |
| //link[@rel=”alternate”] | Extrair conteúdo de elementos contendo o atributo “alternate” |
| //@hreflang | Extrair todos valores de hreflang |
| //head/link[@rel=”amphtml”]/@href | Extrair URL AMP de uma página |
| //head/link[@rel=”alternate”]/@href | Extrair URL do valor alternate |
| //link[contains(@media, ‘640’) and @href]/@href | Estrai href contendo media no elemento |
| //*[@hreflang]/@hreflang | Extrai o valor do hreflang |
| //iframe/@src | Extrai URL do iframe |
| //iframe[contains(@src ,’www.youtube.com/embed/’)] | Extrai URL de vídeos do Youtube incorporado à página |
| //iframe[not(contains(@src, ‘https://www.googletagmanager.com/’))]/@src | Extrai URL que não seja iframe específico |
| //meta[@name=’news_keywords’]/@content | Extrai conteúdo meta “news_keywords” |
| (//iframe/@src)[1] | Extrai URL da primeira ocorrência de iframe |
| //div[@class=”posts”]//a | Extrai o texto âncora dentro de uma div de classe posts. Usar “Extract Inner HTML” |
| //div[@class=”posts”]//a/@href | Extrai o URL dentro de uma div de classe posts. Usar “Extract Inner HTML” |
| //div[@class=”posts”]//a | Extrai código completo do link dentro de uma div com a classe posts. Usar Extract HTML Element |
| //html /@lang | Extrai o idioma da página declarado no elemento HTML |
Extrair as tags de media social de texto como Open Graph ou Twitter Cards
| Exemplo | Descrição |
|---|---|
| Exemplos para extração de tags media social Screaming Frog | |
| //meta[starts-with(@property, “og:title”)][1]/@content | Extrair título |
| //meta[starts-with(@property, “og:description”)][1]/@content | Extrair a descrição |
| //meta[starts-with(@property, “og:type”)][1]/@content | Extrair o tipo do Open Graph ou Twitter Cards, |
| //meta[starts-with(@property, “og:site_name”)][1]/@content | Extrair o valor do nome do site |
| //meta[starts-with(@property, “og:locale”)][1]/@content | Extrair valor da localidade |
| //meta[starts-with(@property, “og:image”)][1]/@content | Extrair URL da imagem |
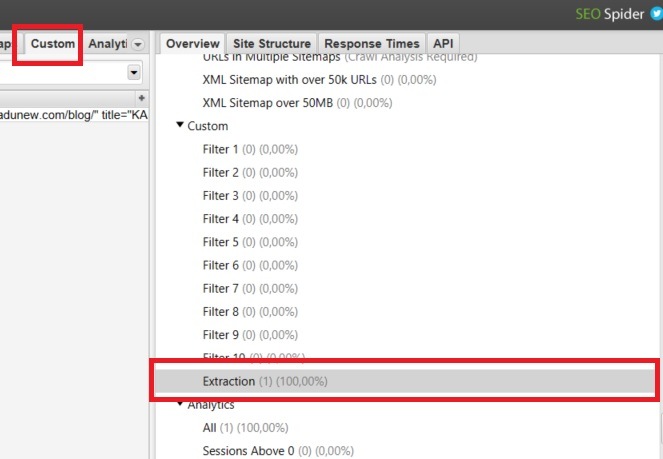
Resultado da Extração
Para acessar o conteúdo extraído pelo Screaming Frog, acesse a aba Custom ou no painel à direita acesse Extraction dentro da seção Custom.
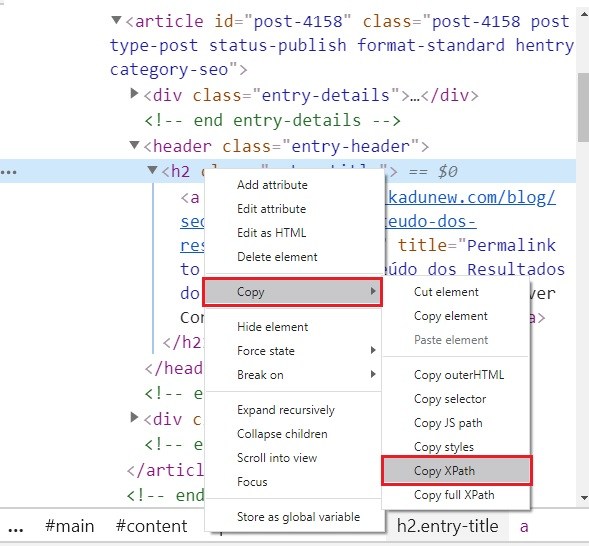
Copiando XPath pelo Navegador
O navegador Google Chrome tem um recurso que facilita a escrita da regra XPath. Você pode usar o recurso através da ferramenta dev Tools para gerar expressões XPath:
- Abra a Dev tools pressionando a tecla F12 (ou botão direito > inspecionar);
- Clique com o botão direito do mouse sobre o elemento desejado;
- Vá em copy > copy XPath;
- Talvez seja necessário adaptar a expressão XPath que Chrome oferece antes de usar no Screaming Frog. Porém, você já tem uma ideia inicial da regra;
- Exemplo de uma regra XPath copiada //*[@id=”post-4158″]/header/h2 (exemplo abaixo).